
The Data Engineer's Guide to Fivetran Alternatives
For Fivetran evaluations and replacements


Introduction
This guide to Fivetran alternatives is continuously evolving. Feel free to add your comments to the article to help improve it. Conversations can also be had on the Estuary Slack workspace and Estuary LinkedIn pages.
This guide is meant for two audiences:
Companies thinking about adopting Fivetran
Companies thinking about replacing Fivetran
Fivetran as a company has been around for over a decade, and as a product in its current shape at least 3 years. While Fivetran is a leading ELT (Extract, Load, and Transform) product, the most common reasons people consider moving away from Fivetran are also reasons you should understand when you evaluate Fivetran the first time:
High latency: Fivetran, like most other ELT vendors, is batch only. This includes its CDC connectors, which read a database source’s transaction log (also known as a write-ahead log or WAL) in batch intervals. While its HVR acquisition added real-time CDC connectors, they are a different product and pipeline from Fivetran.
High, unpredictable costs: Fivetran is not only the most expensive of the modern ELT vendors. It is also the most unpredictable in costs. Some sources require you to replicate all source data. Non-relational sources are converted into highly normalized relational data that gets counted as many more monthly active rows (MAR) than expected. Fivetran customers often don’t understand this until they get the bill.
Reliability: Fivetran implements batch CDC that extracts full snapshots and processes the WAL in batch intervals. Both add stress to a database and have been known to even cause database failures. Alerts, warnings, and failures also lead to additional time spent on handling them.
Support: Related to reliability issues, when things go wrong customers complain support can be slow.
Connectors: Sometimes Fivetran doesn’t have connectivity to a specific source or destination. It’s important to evaluate your connectivity needs before you commit to Fivetran or any other vendor.
This guide compares the following vendors that other companies most commonly consider as alternatives in alphabetical order (so as not to bias.)
Airbyte
Estuary
Fivetran
Hevo
The reason is that like Fivetran the above vendors all support:
ELT, including support for dbt
Change data capture (CDC) and messaging integration
A very large number of connectors as well as a connector SDK
SaaS (not just on premises or managed hosting)
In addition, these vendors also offer better solutions for some of the limitations with Fivetran including:
Real-time streaming and end-to-end low latency
ETL (mid-stream transformations)
Better support
Better end-to-end scalability or reliability
Lower costs
Greater control over data, schema changes, or DataOps
While there is a summary of each vendor, an overview of their architecture, and when to consider them, the detailed comparison is best seen in the comparison matrix, which covers the following categories:
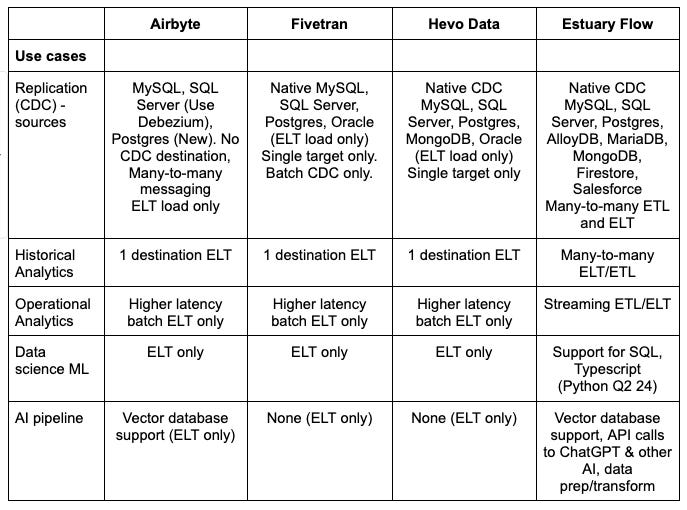
Use cases - replication, historical analytics, operational analytics, data science, and AI
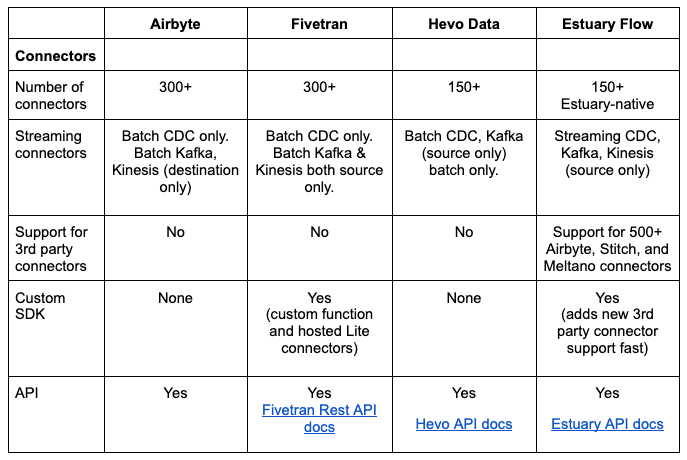
Connectors - packaged, streaming, 3rd party support, SDK, and APIs
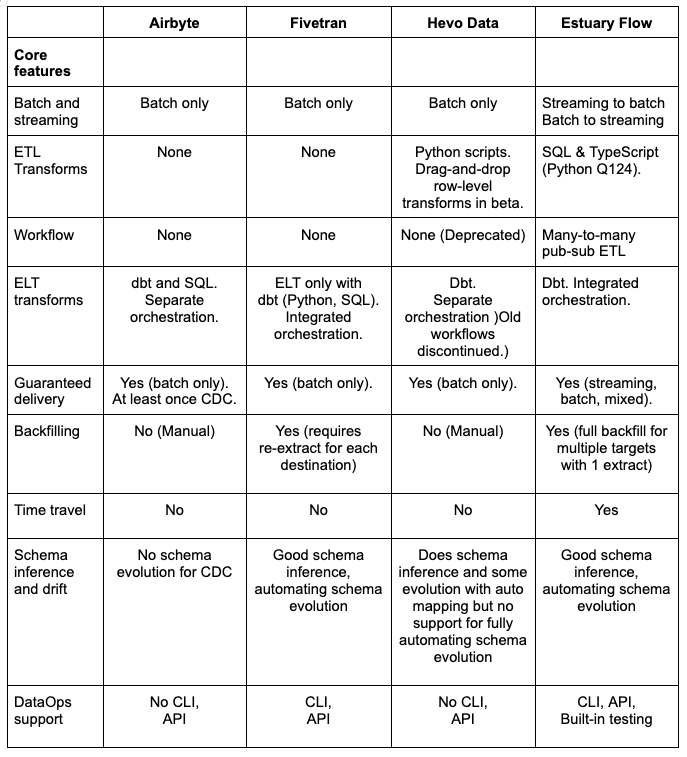
Core features - transforms, languages, streaming+batch modes, guaranteed delivery, backfilling, time travel, data types, schema drift, DataOps
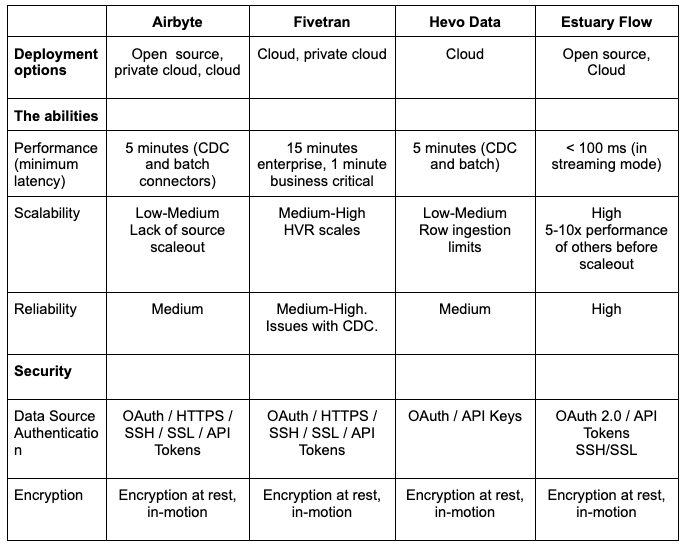
Deployment options - public (multi-tenant) cloud, private cloud, and on-premises
The “abilities” - performance, scalability, reliability, and availability
Security - including authentication, authorization, and encryption
Costs - Both vendor and other costs you need to consider
When replacing Fivetran, some companies evaluate open source options including Airbyte, Hevo Data, or Meltano because they want to bring their integration in-house. I haven’t included Meltano mostly because it doesn’t support CDC. The other option to consider is Debezium, which is actually the only real-time option since Airbyte, Hevo, and Fivetran are all batch-based CDC. All of these require more in-house resources, especially Debezium. This guide will not give you a good answer for on-premises deployments. We are considering creating that guide as well, so please ask.
If you are looking to use the resources you have, the most common approach is to evaluate cloud offerings, which is the main focus of this guide. We have not included Meltano cloud, which is currently in beta, but which also lacks CDC.
Over time, we will also be adding more information about other vendors that at the very least deserve honorable mention, and at the very best should be options you consider for your specific needs. Here’s an initial list I’d like to include (in alphabetical order so as not to give any bias.) We can expand this list based on the demands and feedback from the community.
CData
Debezium
Goldengate
Informatica
Matillion
Meltano
Portable
Rivery
Segment
Striim
Qlik, Talend (acquired by Qlik), and Stitch (acquired by Talend)
It’s OK to choose a vendor that’s good enough. The biggest mistakes you can make are:
Choosing a good vendor for your current project but the wrong vendor for future needs
Not understanding your future needs
Not insulating yourself from a vendor
Make sure to understand and evaluate your future needs and design your pipeline for modularity so that you can replace components, including your ELT/ETL vendor, if necessary.
Hopefully by the end of this guide you will understand the relative strengths and weaknesses of Fivetran and each of the other vendors, and how to evaluate these vendors based on your current and future needs.
Comparison of Fivetran Alternatives
This guide starts with the detailed comparison before moving into an analysis of each vendor’s strengths, weaknesses, and when to use them.
The following comparison matrix covers the following categories:
Use cases - Over time, companies end up using data integration for most of these use cases. Make sure you look across your organization for current and future needs. Otherwise you will either end up with multiple data integration technologies, or a painful migration project.
Replication (CDC) - Streaming 1-to-1 replication of data from source(s) to target(s), usually for operational use cases such as offloading reads from a (write) master.
Historical analytics - the use of data warehouses for dashboards, analytics, and reporting. ETL or ELT based data integration is used to feed the data warehouse.
Operational analytics - the use of data in real-time to make operational decisions. It requires specialized databases with sub-second query times, and usually also requires low end-to-end latency with sub-second ingestion times as well. For this reason the data pipelines usually need to support real-time ETL with streaming transformations.
Data science - the use of raw structured and unstructured data, most commonly loaded into a data lake, to support experts as they try to discover new insights using advanced analytics, statistics, machine learning and other AI techniques.
AI - the use of large language models (LLM) or other artificial intelligence and machine learning models to do anything from generating new content to automating decisions. This usually involves different data pipelines for model training, and model execution.
Connectors - The ability to connect to sources and destinations in batch and real-time for different use cases. Most vendors have so many connectors that the best way to evaluate vendors is to pick your connectors and evaluate them directly in detail.
Number of connectors - The number of source and target connectors. Make sure to evaluate each vendor’s specific connectors and their capabilities for your projects.
Streaming (CDC, Kafka) - All vendors support batch. The biggest difference is how much each vendor supports streaming.
Support for 3rd party connectors - Is there an option to use 3rd party connectors?
CDK - Can you build your own connectors using a connector development kit (CDK)?
API - Is an API available to integrate with the vendor?
Core features - How well does each vendor support core data features required to support different use cases? Source and target connectivity is covered in the Connectors section.
Batch and streaming support - Can the product support streaming, batch, and both together in the same pipeline?
Transformations - What level of support is there for streaming and batch ETL and ELT? This includes streaming transforms, and incremental and batch dbt support in ELT mode. What languages are supported? How do you test?
Guaranteed delivery - Is delivery guaranteed to be exactly once, and in order.
Data types - Support for structured, semi-structured, and unstructured data types.
Backfilling - The ability to add historical data during integration, or later additions of new data in targets.
Time travel - The ability to review or reuse historical data without going back to sources.
Schema drift - support for tracking schema changes over time, and handling it automatically.
DataOps - Does the vendor support multi-stage pipeline automation?
Deployment options - does the vendor support public (multi-tenant) cloud, private cloud, and on-premises (self-deployed)?
The “abilities” - How does each vendor rank on performance, scalability, reliability, and availability?
Performance (latency) - what is the end-to-end latency in real-time and batch mode?
Scalability - Does the product provide elastic, linear scalability
Reliability - How does the product ensure reliability for real-time and batch modes? One of the biggest challenges, especially with CDC, is ensuring reliability.
Security - Does the vendor implement strong authentication, authorization, RBAC, and end-to-end encryption from sources to targets?
Costs - the vendor costs, and total cost of ownership associated with data pipelines
Vendor costs - including total costs and cost predictability
Labor costs - Amount of resources required and relative productivity
Other costs - Including additional source, pipeline infrastructure or destination costs
Fivetran
If you want to understand and evaluate Fivetran and the alternatives, it’s important to know Fivetran’s history. It will help you understand Fivetran’s strengths and weaknesses relative to other vendors.
Fivetran was founded in 2012 by data scientists who wanted an integrated stack to capture and analyze data. The name was a play on Fortran and meant to refer to a programming language for big data. After a few years the focus shifted to providing just the data integration part because that’s what so many prospects wanted. Fivetran was designed as an ELT (Extract, Load, and Transform) architecture because in data science you don’t usually know what you’re looking for, so you want the raw data.
In 2018, Fivetran raised their series A, and then added more transformation capabilities in 2020 when it released Data Build Tool (dbt) support. That year Fivetran also started to support CDC. Fivetran has since continued to invest more in CDC with its HVR acquisition.
Fivetran’s design worked well for many companies adopting cloud data warehouses starting a decade ago. While all ETL vendors also supported “EL” and it was occasionally used that way, Fivetran was cloud-native, which helped make it much easier to use. The “EL” is mostly configured, not coded, and the transformations are built on dbt core (SQL and Jinja), which many data engineers are comfortable using.
But today Fivetran often comes in conversations as a vendor customers are trying to replace. Understanding why can help you understand Fivetran’s limitations.
The most common points that come up in these conversations and online forums are about needing lower latency, improved reliability, and lower, more predictable costs:
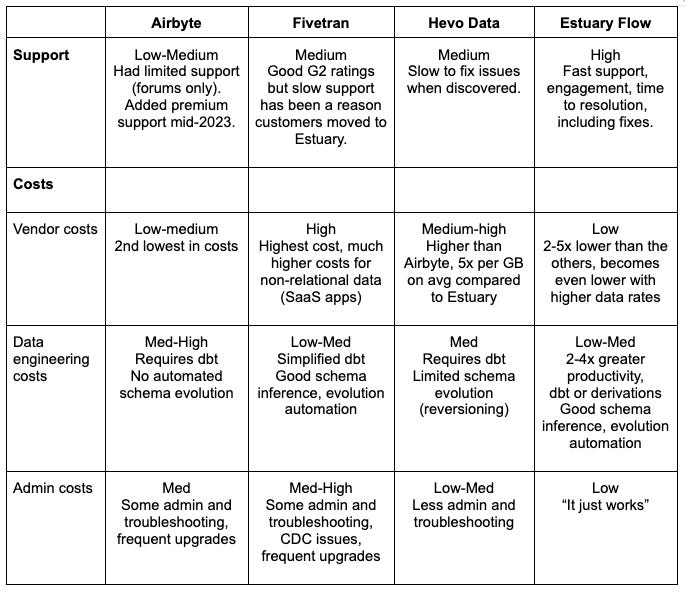
Latency: While Fivetran uses change data capture at the source, it is batch CDC, not streaming. Enterprise-level is guaranteed to be 15 minutes of latency. Business critical is 1 minute of latency, but costs more than 2x the standard edition. Its ELT architecture can also be slowed down by the target load and transformation times.
Costs: Another major complaint are Fivetran’s high vendor costs, which have been 5x the cost of Estuary as stated by customers. Fivetran costs are based on monthly active rows (MAR) that change at least once per month. This may seem low, but for several reasons (see below) it can quickly add up.
Lower latency is also very expensive. To reduce latency from 1 hour to 15 minutes can cost you 33-50% more (1.5x) per million MAR, and 100% (2x) or more ro reduce latency to 1 minute. Even then, you still have the latency of the data warehouse load and transformations. The additional costs of frequent ingestions and transformations in the data warehouse can also be expensive and take time. Companies often keep latency high to save money.Unpredictable costs: Another major reason for high costs is that MARs are based on Fivetran’s internal representation of rows, not rows as you see them in the source.
For some data sources you have to extract all the data across tables, which can mean many more rows. Fivetran also converts data from non-relational sources such as SaaS apps into highly normalized relational data. Both make MARs and costs unexpectedly soar. This also does not account for the initial load where all rows count.Reliability: Another reason for replacing Fivetran is reliability. Customers have struggled with a combination of alerts of load failures, and subsequent support calls that result in a longer time to resolution. There have been several complaints about reliability with MySQL and Postgres CDC, which is due in part because Fivetran uses batch CDC. Fivetran also had a 2.5 day outage in 2022. Make sure you understand Fivetran’s current SLA in detail. Fivetran has had an “allowed downtime interval” of 12 hours before downtime SLAs start to go into effect on the downtime of connectors. They also do not include any downtime from their cloud provider.
Support: Customers also complain about Fivetran support being slow to respond. Combined with reliability issues, this can lead to a substantial amount of data engineering time being lost to troubleshooting and administration.
DataOps: Fivetran does not provide much control or transparency into what they do with data and schema. They alter field names and change data structures and do not allow you to rename columns. This can make it harder to migrate to other technologies. Fivetran also doesn’t always bring in all the data depending on the data structure, and does not explain why.
Roadmap: Customers frequently comment Fivetran does not reveal as much of a future direction or roadmap compared to the others in this comparison, and do not adequately address many of the above points.
Airbyte
Airbyte was founded in 2020 as an open source data integration company, and launched its cloud service in 2022.
While this section is about Airbyte, you could include Stitch and Meltano here because they all support the Singer framework. Stitch created the Singer open source ETL project and built their offering around it. Stitch then got acquired by Talend, which in turn was acquired by Qlik. This left Singer without a major company driving its innovation. Instead, there are several companies who use the connectors. Meltano is one of those. They have built on the Stitch taps (connectors) and other open source projects.
Airbyte started as a Singer-based ELT tool, but has since changed their protocol and connectors to be different. Airbyte has kept Singer compatibility so that it can support Singer taps as needed. Airbyte has also kept many of the same principles, including being batch-based. This is eventually where Airbyte’s limitations come from as well.
Airbyte has become one of the main alternatives to consider when replacing Fivetran if you’re concerned about cost or are considering self-hosted open source. If you go by pricing calculators and customers, it’s the second lowest cost vendor in the evaluation after Estuary. Most of the companies we’ve talked to were considering cloud options, so we’ll focus on Airbyte cloud.
Latency: While Airbyte has CDC source connectors mostly built on Debezium (except for a new Postgres CDC connector), and also has Kafka and Kinesis source connectors, everything is loaded in intervals of 5 minutes or more. There is no staging or storage, so if something goes wrong with either source or target the pipeline stops. Airbyte is pulling from source connectors in batch intervals. When using CDC, this can put a load on the source databases. In addition, because all Airbyte CDC connectors (other than the new Postgres connector) use Debezium, it is not exactly-once, but at-least-once guaranteed delivery. Latency is also made worse with batch ELT because you need to wait for loads and transforms in the target data warehouse.
Reliability: There are some issues with reliability you will need to manage. Most CDC sources, because they’re built on Debezium, only ensure at-least-once delivery. It means you will need to deduplicate (dedup) at the target. Airbyte does have both incremental and deduped modes you can use though. You just need to remember to turn them on. Also, Debezium does put less of a load on a source because it uses Kafka. This does make it less of a load on a source than Fivetran CDC. A bigger reliability issue is failure of under-sized workers. There is no scale-out option. Once a worker gets overloaded you will have reliability issues (see scalability.) There is also no staging or storage within an Airbyte pipeline to preserve state. If you need the data again, you’ll have to re-extract from the source.
Scalability: Airbyte is not known for scalability. It has scalability issues that may not make it suitable for your larger workloads. For example, each airbyte operation of extracting from a source or loading into a target is done by one worker. The source worker is generally the most important component, and its most important component is memory. The source worker will read up to 10,000 records into memory, which could lead to GBs of RAM. By default only 25% of each instance’s memory is allocated to the worker container, which you have little control over in Airbyte Cloud.
Airbyte is working on scalability. The new PostgreSQL CDC connector does have improved performance. Its latest benchmark as of the time of this writing produced 9MB/sec throughput, higher than Fivetran’s (non HVR) connector. But this is still only 0.5TB a day or so depending on how loads vary throughout the day.ELT only: Airbyte cloud supports dbt cloud. This is different from dbt core used by Fivetran. If you have implemented on dbt core in a way that makes it portable (which you should) the move can be relatively straightforward. But if you want to implement transforms outside of the data warehouse, Airbyte does not support that.
DataOps: Airbyte provides UI-based replication designed for ease of use. It does not give you an “as code” mode that helps with automating end-to-end pipelines, adding tests, or managing schema evolution.
Hevo Data
Hevo is a cloud-based ETL/ELT service for building data pipelines that, unlike Fivetran, started as a cloud service in 2017, which makes it more mature than Airbyte. Like Fivetran, Hevo is designed for “low code”, though it does provide a little more control to map sources to targets, or add simple transformations using Python scripts or a new drag-and-drop editor (currently in Beta) in ETL mode. Stateful transformations such as joins or aggregations, like Fivetran, should be done using ELT with SQL or dbt.
While Hevo is a good option for someone getting started with ELT, as one user put it, “Hevo has its limits.”
Connectivity: Hevo has the lowest number of connectors at slightly over 150. While this is a lot, it means you need to think about what sources and destinations you need for your current and future projects to make sure it will support your needs.
Latency: Hevo is still mostly batch-based connectors on a streaming Kafka backbone. While data is converted into “events” that are streamed, and streams can be processed if scripts are written for any basic row-level transforms, Hevo connectors to sources, even when CDC is used, is batch. There are starting to be a few exceptions. For example, you can use the streaming API in BigQuery, not just the Google Cloud Storage staging area. But you still have a 5 minute or more delay at the source. Also, there is currently no common scheduler. Each source and target frequency is different. So latency can be longer than the source or target when they operate at different intervals.
Costs: Hevo can be comparable to Estuary for low data volumes in the low GBs per month. But it becomes more expensive than Estuary and Airbyte as you reach 10s of GBs a month. Costs will also be much more as you lower latency because several Hevo connectors do not fully support incremental extraction. As you reduce your extract interval you capture more events multiple times, which can make costs soar.
Reliability: CDC is batch mode only, with the minimum interval being 5 minutes. This can load the source and even cause failures. Customers have complained about Hevo bugs that make it into production and cause downtime.
Scalability: Hevo has several limitations around scale. Some are adjustable. For example, you can get the 50MB Excel, and 5GB CSV/TSV file limits increased by contacting support.
But most limitations are not adjustable, like column limits. MongoDB can hit limits more often than others. A standalone MongoDB instance without replicas is not supported. You need 72 hours or more of OpsLog retention. And there is a 4090 columns limit that is more easily hit with MongoDB documents.
There are ingestion limits that cause issues, like a 25 million row limit per table on initial ingestion. In addition there are scheduling limits that customers hit, like not being able to have more than 24 custom times.
For API calls, you cannot make more than 100 API calls per minute.DataOps: Like Airbyte, Hevo is not a great option for those trying to automate data pipelines. There is no CLI or “as code” automation support with Hevo. You can map to a destination table manually, which can help. But while there is some built-in schema evolution that happens when you turn on auto mapping, you cannot fully automate schema evolution or control the rules. There is no schema testing or evolution control. New tables can be passed through, but many column changes can lead to data not getting loaded in destinations and moved to a failed events table that must be fixed within 30 days or the data is permanently lost. Hevo used to support a concept of internal workflows, but it has been discontinued for new users. You cannot modify folder names for the same “events”.
One final note. Hevo does have a way to support reverse ETL. I did not include it here because it is a very specific use case where you write modified data back directly into the source. This does work if you’re using a data warehouse to cleanse data. But that is not how updates work in most cases for applications. The better answer is to have a pipeline back to the sources, which is not supported by most modern ETL/ELT vendors. It is supported by iPaaS vendors.
Estuary
Estuary was founded in 2019. But the core technology, the Gazette open source project, has been evolving for a decade within the Ad Tech space, which is where many other real-time data technologies have started.
Estuary is the only real-time and ETL data pipeline vendor in this comparison. There are some other ETL and real-time vendors in the honorable mention section, but those are not as viable a replacement for Fivetran.
While Estuary is also a great option for batch sources and targets and supports all Fivetran use cases, where it really shines is any combination change data capture (CDC), real-time and batch ETL or ELT, and multiple destinations.
CDC works by reading record changes written to the write-ahead log (WAL) that records each record change exactly once as part of each database transaction. It is the easiest, lowest latency, and lowest-load for extracting all changes, including deletes, which otherwise are not captured by default from sources. Unfortunately Airbyte, Fivetran, and Hevo all rely on batch mode for CDC. This puts a load on a CDC source by requiring the write-ahead log to hold onto older data. This is not the intended use of CDC and can put a source in distress, or lead to failures.
Estuary has a unique architecture where it streams and stores streaming or batch data as collections of data, which are transactionally guaranteed to deliver exactly once from each source to the target. With CDC it means any (record) change is immediately captured once for multiple targets or later use. Estuary uses collections for transactional guarantees and for later backfilling, restreaming, transforms, or other compute. The result is the lowest load and latency for any source, and the ability to reuse the same data for multiple real-time or batch targets across analytics, apps, and AI, or for other workloads such as stream processing, or monitoring and alerting.
Estuary also supports the broadest packaged and custom connectivity. It has 150+ native connectors that are built for low latency and/or scale. While may seem low, these are connectors built for low latency and scale. In addition, Estuary is the only vendor to support Airbyte, Meltano, and Stitch connectors as well, which easily adds 500+ more connectors. Getting official support for the connector is a quick “request-and-test” with Estuary to make sure it supports the use case in production. Most of these connectors are not as scalable as Estuary-native or Fivetran connectors, so it’s important to confirm they will work for you. Its support for TypeScript, SQL, and Python (planned for Q2 2024) also makes it the best vendor for custom connectivity when compared to Fivetran functions, for example.
The three most common Fivetran replacement scenarios are:
Replacing pipelines with CDC sources due to reliability and cost issues
Replacing high monthly active row (MAR) pipelines due to costs.
New projects where Fivetran does not support certain connectors
Most CDC replacements are fast, because they are relational databases, so the data models remain the same. The most common, and fastest approach has been to reuse any dbt core work and initially just use Estuary for “EL”. Companies have been able to do this in a few days to a few weeks from start to production. If you have implemented your dbt core transforms to be portable and independent of Fivetran, it makes future replacements easy. Making each component in your pipeline portable is always recommended.
High MAR sources can be a little more difficult. The reason for the higher cost is because Fivetran is turning non-relational sources into highly normalized tables that break up a single changing row into multiple rows across tables. Estuary and other vendors do not significantly alter the data this way.. So you need to plan for some extra work. Luckily, most deployments have then used dbt core to transform into the right target format, so the extra work in EL mode becomes creating new dbt transforms to load the same target. Because of this, if you start by just replacing the high MAR subsets of your pipeline, you can end up with the largest savings in a shorter period of time.
Estuary is the lowest cost option. Costs from lowest to highest tend to be Estuary, Airbyte, Hevo, and Fivetran in this order, especially for higher volume use cases. Estuary is the lowest cost mostly because Estuary only charges $1 per GB of data moved from each source or to each target, which is much less than the roughly $10-$50 per GB that others charge. Your biggest cost is generally your data movement.
While open source is free, and for many it can make sense, you need to add in the cost of support from the vendor, specialized skill sets, implementation, and maintenance to your total costs to compare. Without these skill sets, you will put your time to market and reliability at risk. Many companies will not have access to the right skill sets to make open source work for them.
How to choose the best option
For the most part, if you are interested in a cloud option, and the connectivity options exist, you may choose to evaluate Estuary as a Fivetran alternative or replacement. There are in fact many Estuary customers who started with Fivetran.
Lowest latency: Estuary is the only ELT/ETL vendor in this comparison with sub-second latency.
Highest scale: It may not be obvious until you run your own benchmarks. But Estuary is the most scalable, especially with CDC. It is the only vendor capable of doing incremental snapshots and has demonstrated 5-10x the scale of Airbyte, Fivetran, and Hevo. If you expect to move a terabyte a day from a source, Estuary is the only option.
Most efficient: Estuary alone has the fastest and most efficient CDC connectors. It is also the only vendor to enable exactly-and-only-once capture, which puts the least load on a system, especially when you’re supporting multiple destinations including a data warehouse, high performance analytics database, and AI engine or vector database.
Most reliable: Estuary’s exactly-once transactional deliver and durable stream storage is partly what makes it the most reliable data pipeline vendor as well.
Lowest cost: for data at any volume, Estuary is the clear low-cost winner.
Great support: Customers moving from Fivetran to Estuary consistently cite great support as one of the reasons for adopting Estuary.
There are good reasons to pick some other vendors:
Private cloud: while it is planned, Estuary currently does not support private cloud or on premises deployments. The current options would be Airbyte or Debezium, or some of the honorable mentions that started as on premises, including Informatica, Matillion, or Talend.
Open source: Estuary is built on open source, but it is a cloud offering. Estuary does not provide support for open source. If open source is a requirement, you might look to Airbyte for batch or Debezium for real-time as your best real-time options.
Ultimately the best approach for evaluating your options is to identify your future and current needs for connectivity, key data integration features, and performance, scalability, reliability, and security needs, and use this information to a good short-term and long-term solution for you.
Getting Started with Estuary
Getting started with Estuary is simple. Sign up for a free account: https://dashboard.estuary.dev/register
Make sure you read through the documentation, especially the get started section:
I highly recommend you also join the Slack community. It’s the easiest way to get support while you’re getting started.
https://dashboard.estuary.dev/register
If you an introduction and walk-through of Estuary to can watch Estuary 101:
https://try.estuary.dev/webinar-estuary101-ondemand/
Questions? Feel free to contact us any time!
https://estuary.dev/about/#contact-us
Originally published on Estuary. https://estuary.dev/fivetran-alternatives-guide/
We're using Fivetran for its Teleport synch capability because we don't have the bin log enabled. Encountering some issues, source db needs to reboot every few weeks to lower the synch timings. Synch timings increase 10 mins every subsequent synch.